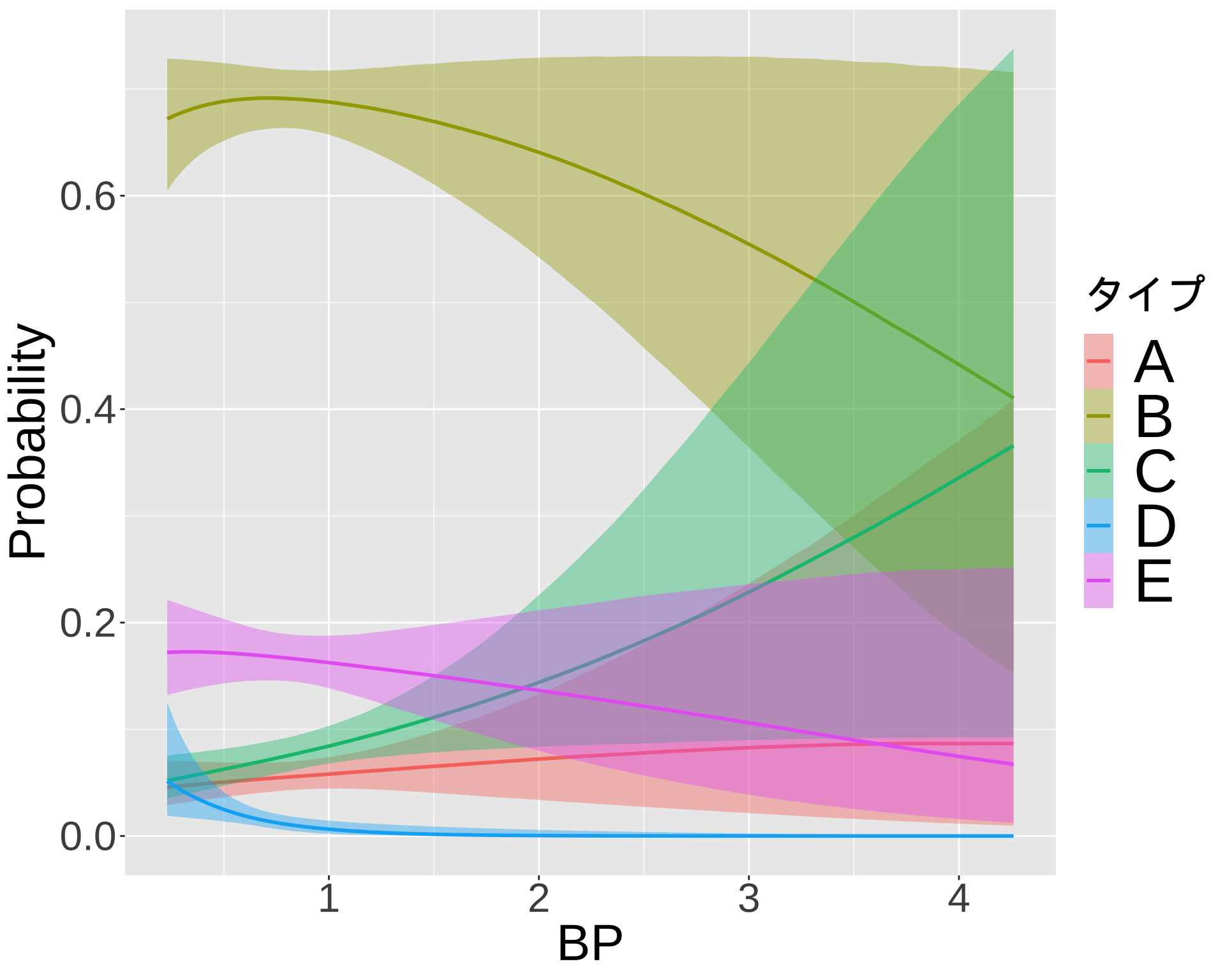
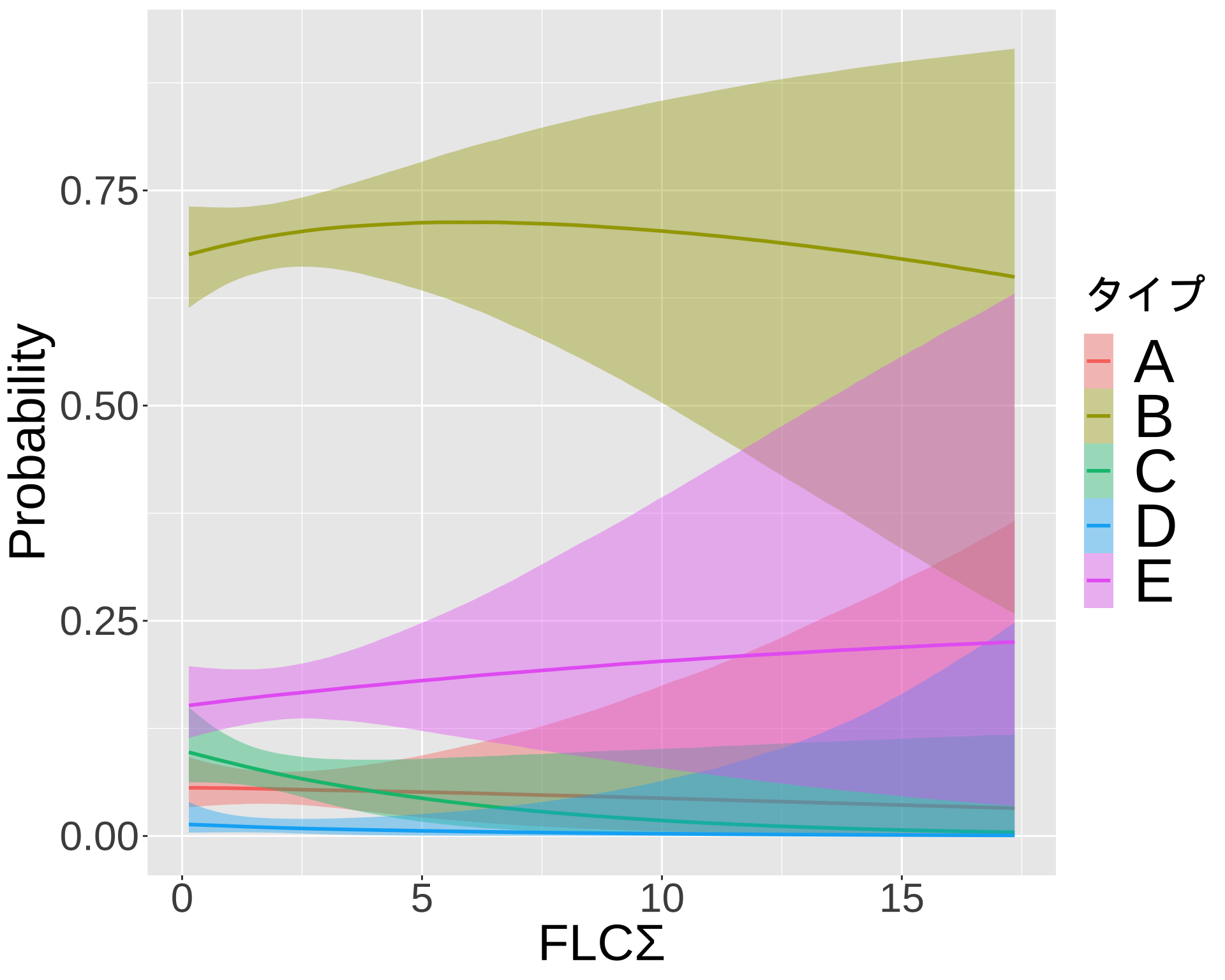
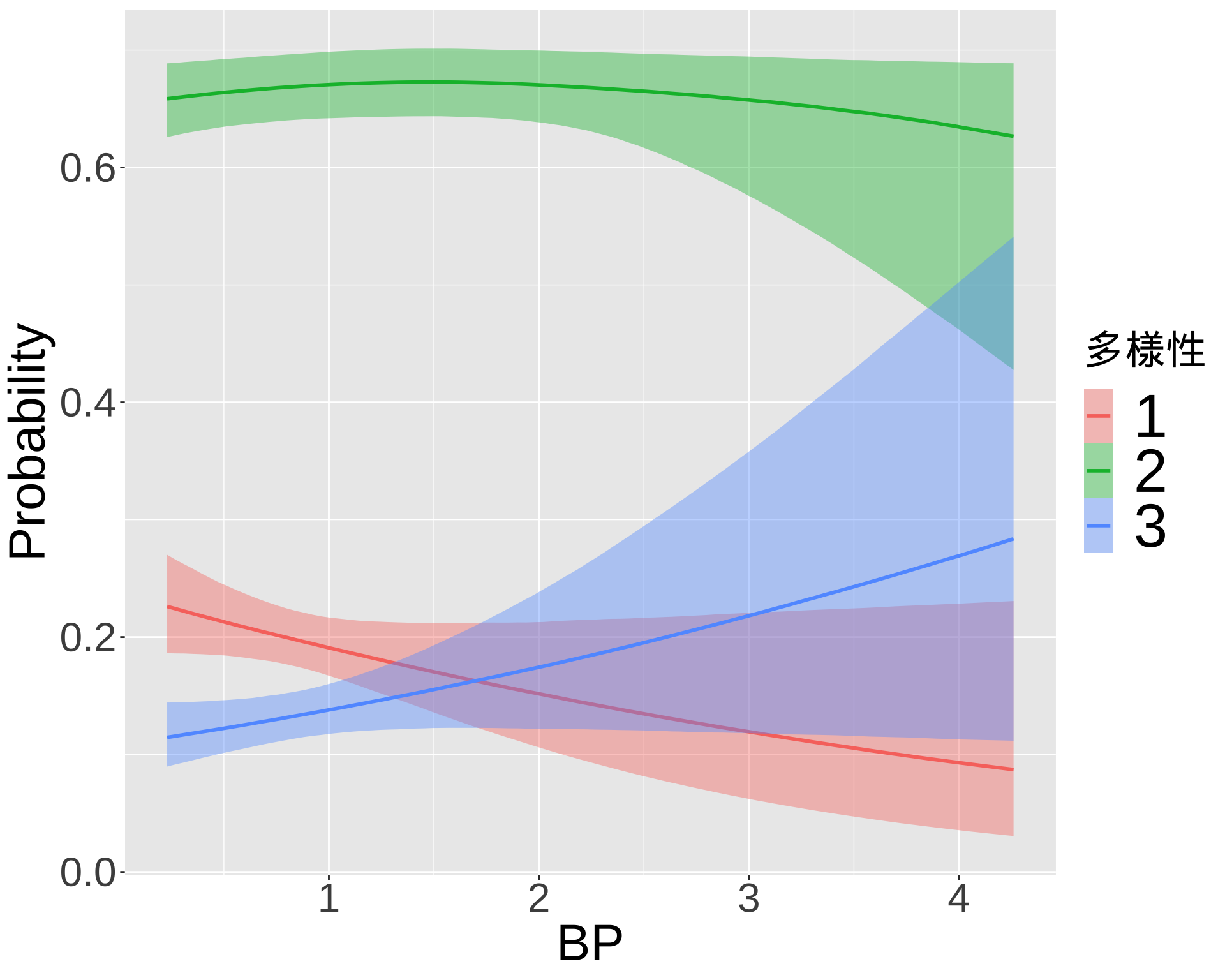
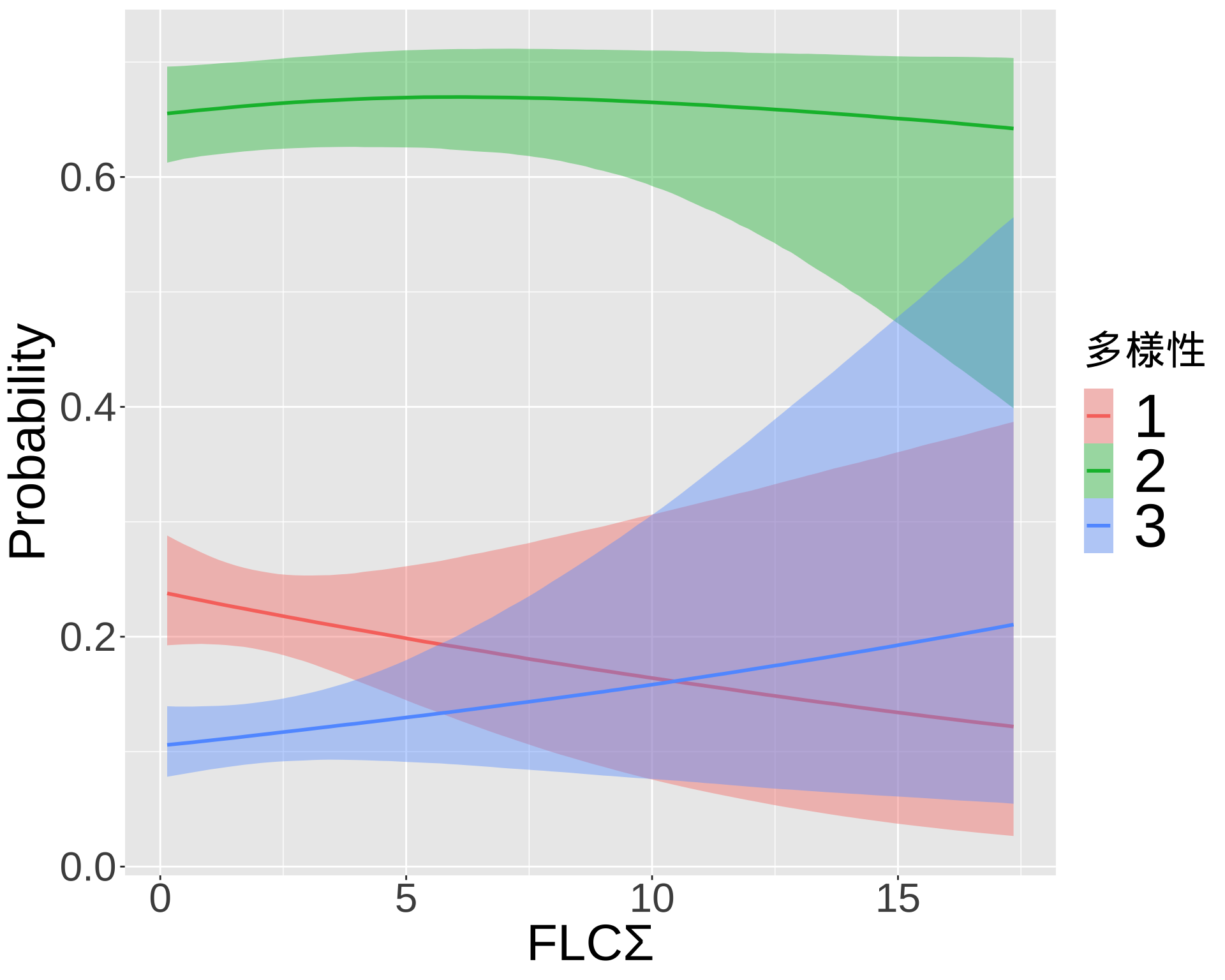
library(readxl)
library(knitr)
df <- readRDS("df.rds")
kable(head(df))| 受付番号 | 受診日年齢 | 性別 | Weight | BP | FLCΣ | BP備考 | 判別式 | LOX-1_H | LAB_H | LOX-index_H | タイプ | 多様性 | item1 | item2 | item3 | item4 | item5 | item6 | item7 | item8 | item9 | item10 | item11 | item12 | item13 | item14 | item15 | item16 | item17 | item18 | BP_A_flag | 年代 | 活気 | イライラ感 | 疲労感 | 不安感 | 抑うつ感 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 48 | 2 | 52.7 | 0.47 | 0.81 | B | -3.343 | 75 | 2.2 | 165 | B | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 4 | 3 | 2 | 3 | 2 | 2 | 2 | 2 | 1 | 2 | 3 | 2 | 0 | 40代 | 3 | 3 | 4 | 3 | 3 |
| 3 | 53 | 2 | 64.8 | 0.67 | -0.30 | BDG | -2.727 | 55 | 2.8 | 154 | A | 1 | 3 | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 3 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 0 | 50代 | 4 | 2 | 4 | 3 | 2 |
| 4 | 46 | 1 | 76.3 | 1.10 | 1.95 | NA | -2.974 | 136 | 3.8 | 517 | B | 2 | 2 | 3 | 3 | 2 | 2 | 2 | 1 | 1 | 2 | 2 | 2 | 1 | 2 | 2 | 1 | 1 | 1 | 1 | 0 | 40代 | 2 | 3 | 2 | 3 | 2 |
| 5 | 65 | 1 | 72.4 | 0.88 | -8.96 | D | -7.338 | 58 | 2.3 | 133 | C | 2 | 3 | 3 | 3 | 2 | 2 | 2 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 60代 | 2 | 3 | 1 | 2 | 1 |
| 6 | 30 | 1 | 59.5 | 0.76 | 0.64 | NA | -2.776 | 46 | 2.2 | 101 | B | 2 | 2 | 2 | 2 | 3 | 4 | 3 | 3 | 3 | 3 | 4 | 4 | 3 | 3 | 3 | 3 | 3 | 1 | 1 | 0 | 30代 | 3 | 5 | 4 | 5 | 4 |
| 7 | 51 | 1 | 76.6 | 1.69 | 2.58 | NA | -2.377 | 78 | 3.2 | 250 | B | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 0 | 50代 | 3 | 3 | 3 | 3 | 2 |