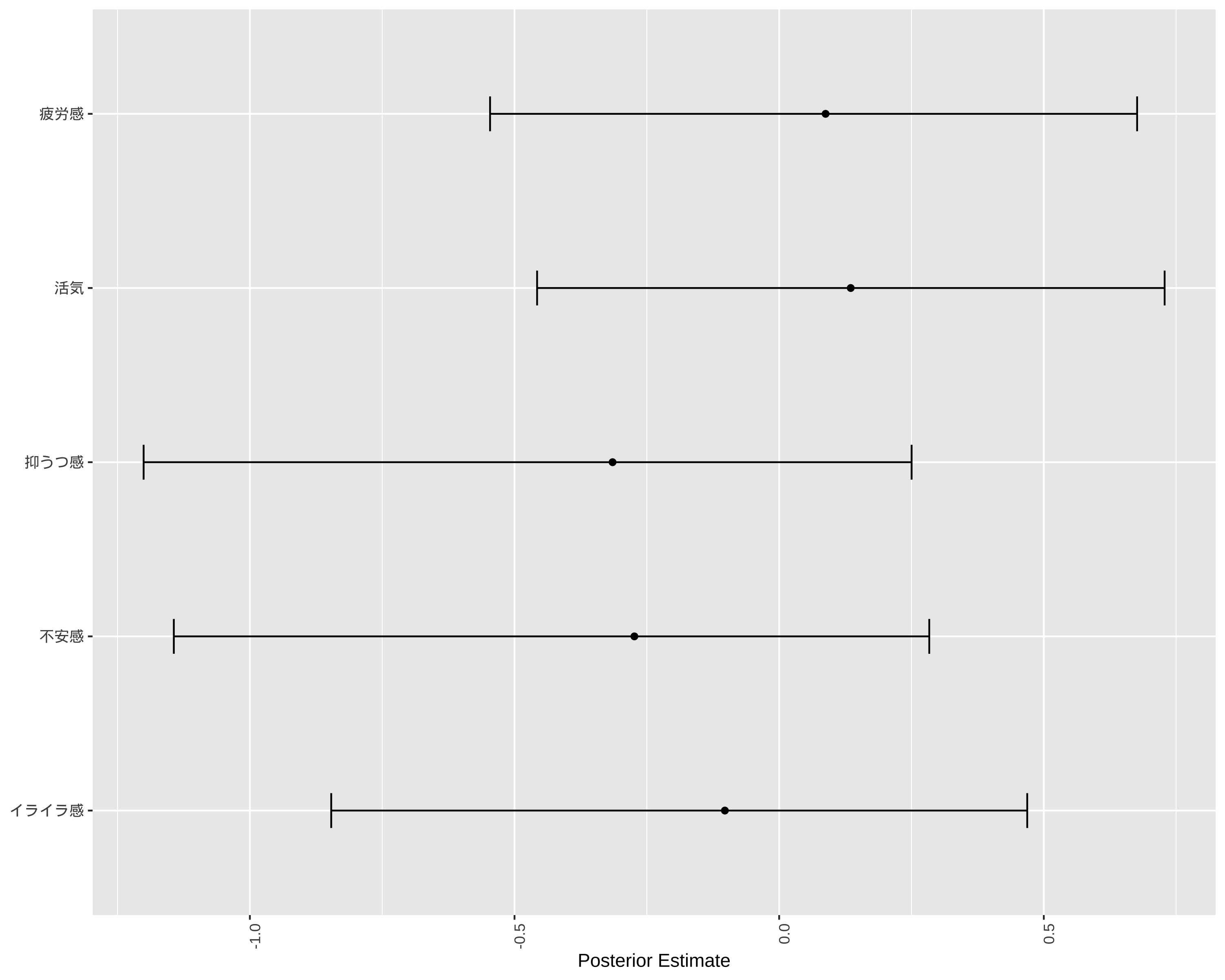
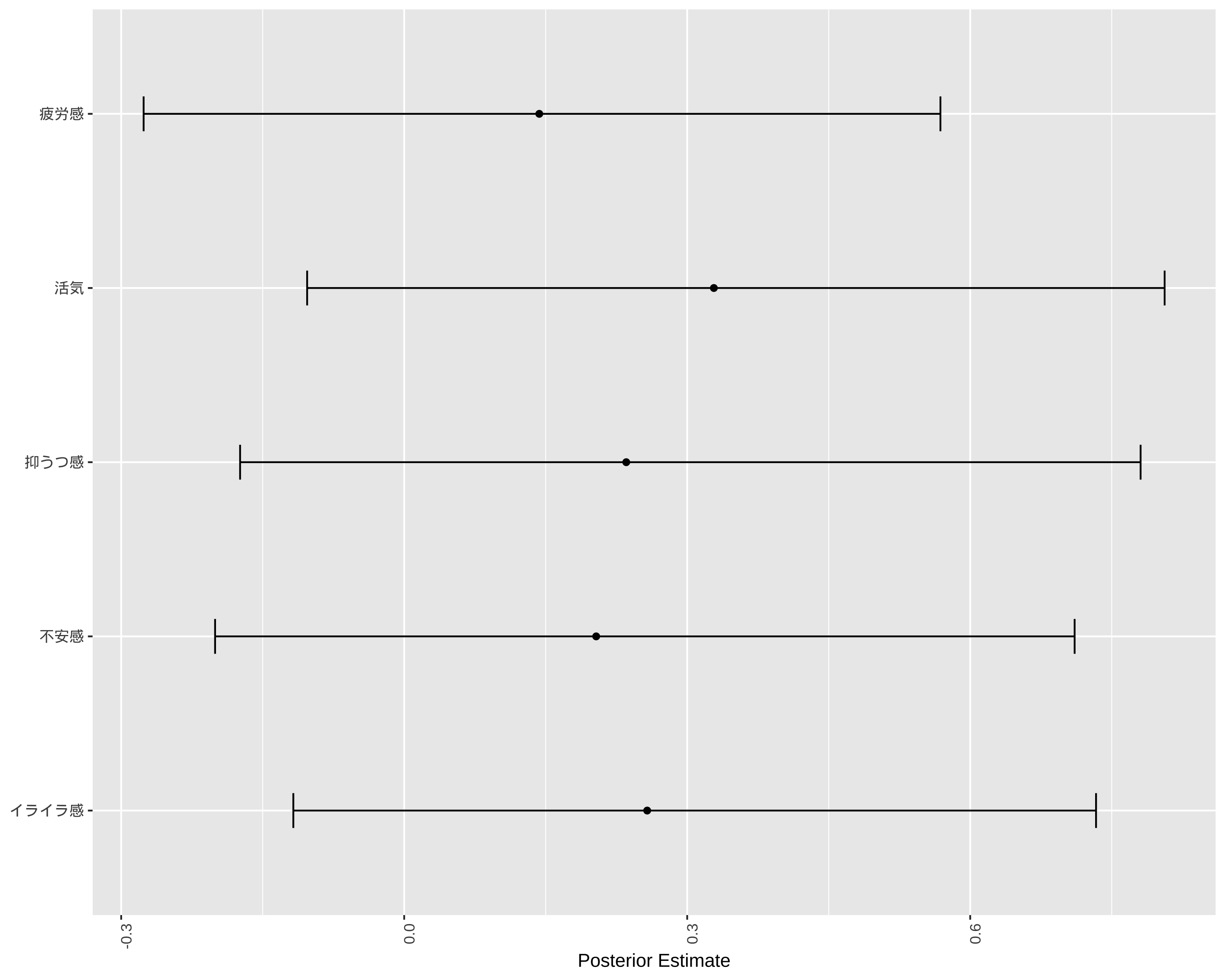
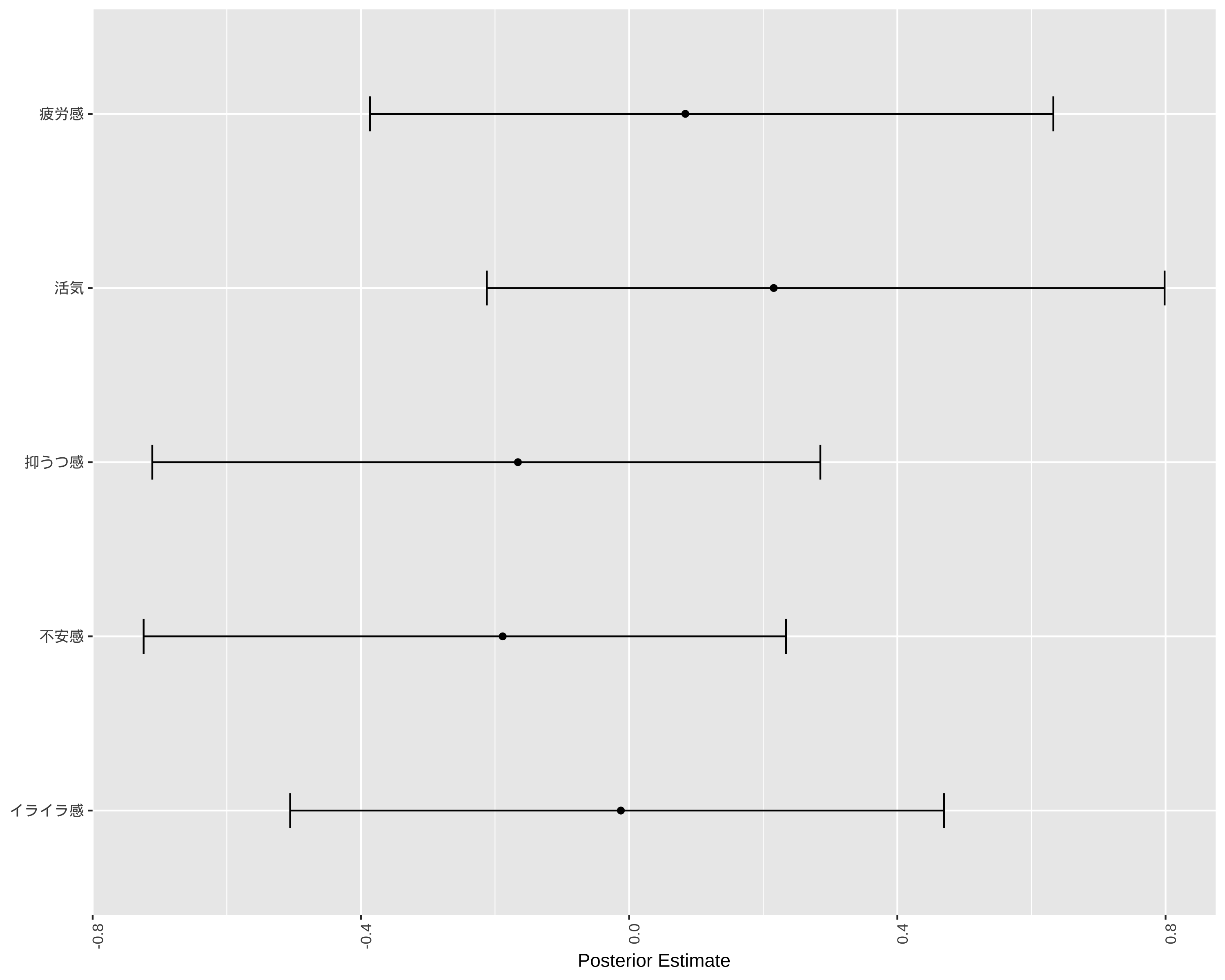
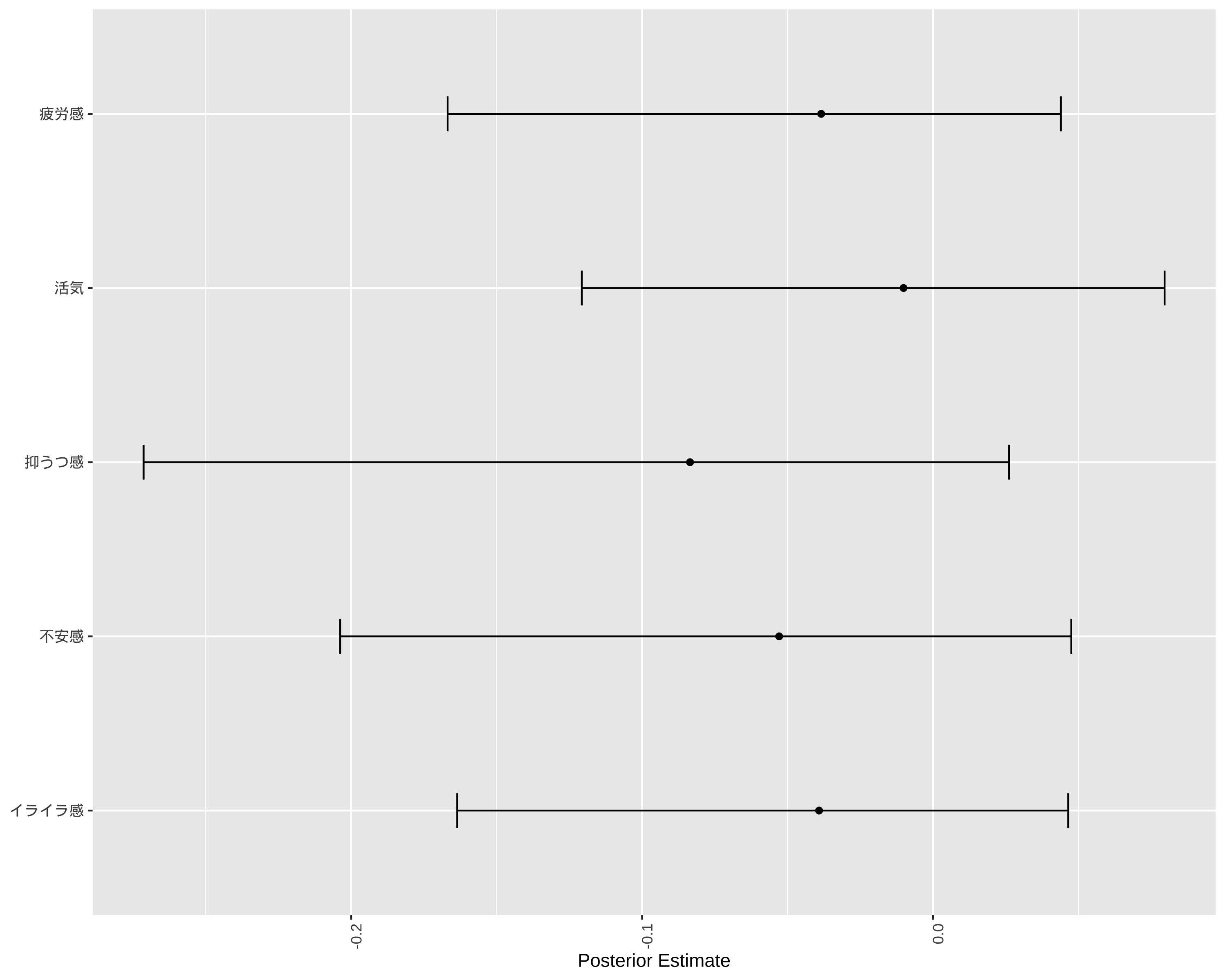
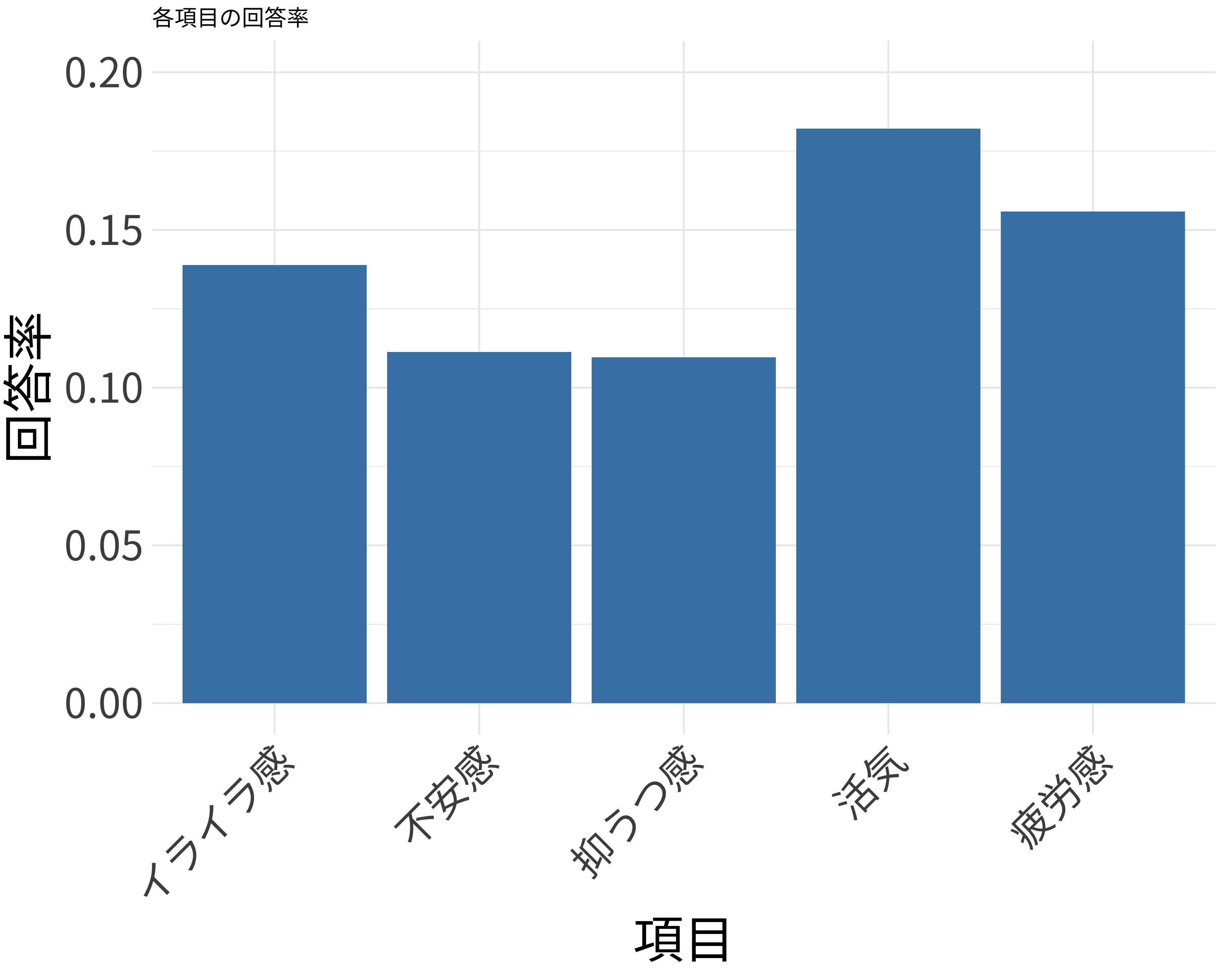
# 各項目の回答率を計算
response_rates <- c(
mean(res_疲労感),
mean(res_活気, na.rm = TRUE),
mean(res_抑うつ感),
mean(res_不安感),
mean(res_イライラ感, na.rm = TRUE)
)
# 項目名のベクトル
item_names <- c("疲労感", "活気", "抑うつ感", "不安感", "イライラ感")
# データフレームの作成
plot_data <- data.frame(
item = item_names,
rate = response_rates
)
# 棒グラフの作成
ggplot(plot_data, aes(x = item, y = rate)) +
geom_bar(stat = "identity", fill = "steelblue") +
theme_minimal() +
labs(
title = "各項目の回答率",
x = "項目",
y = "回答率"
) +
theme(
axis.text.x = element_text(angle = 45, hjust = 1),
text = element_text(family = "notosans"),
axis.text = element_text(size = 24),
axis.title = element_text(size = 30),
legend.text = element_text(size = 36),
legend.title = element_text(size = 24),
# plot.margin = margin(r = 20, l = 10)
) +
ylim(0, 0.2) # y軸の範囲を0から1に設定