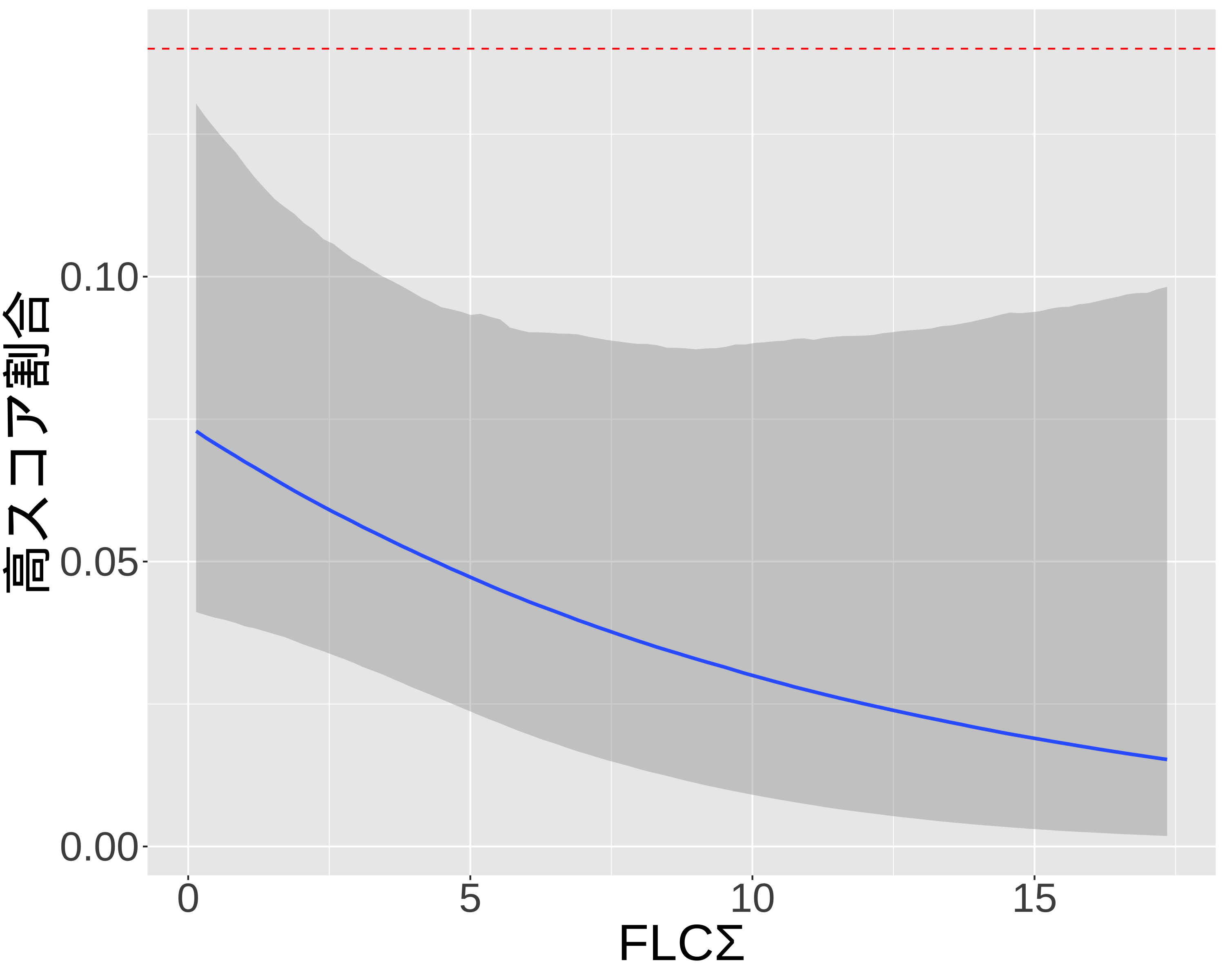
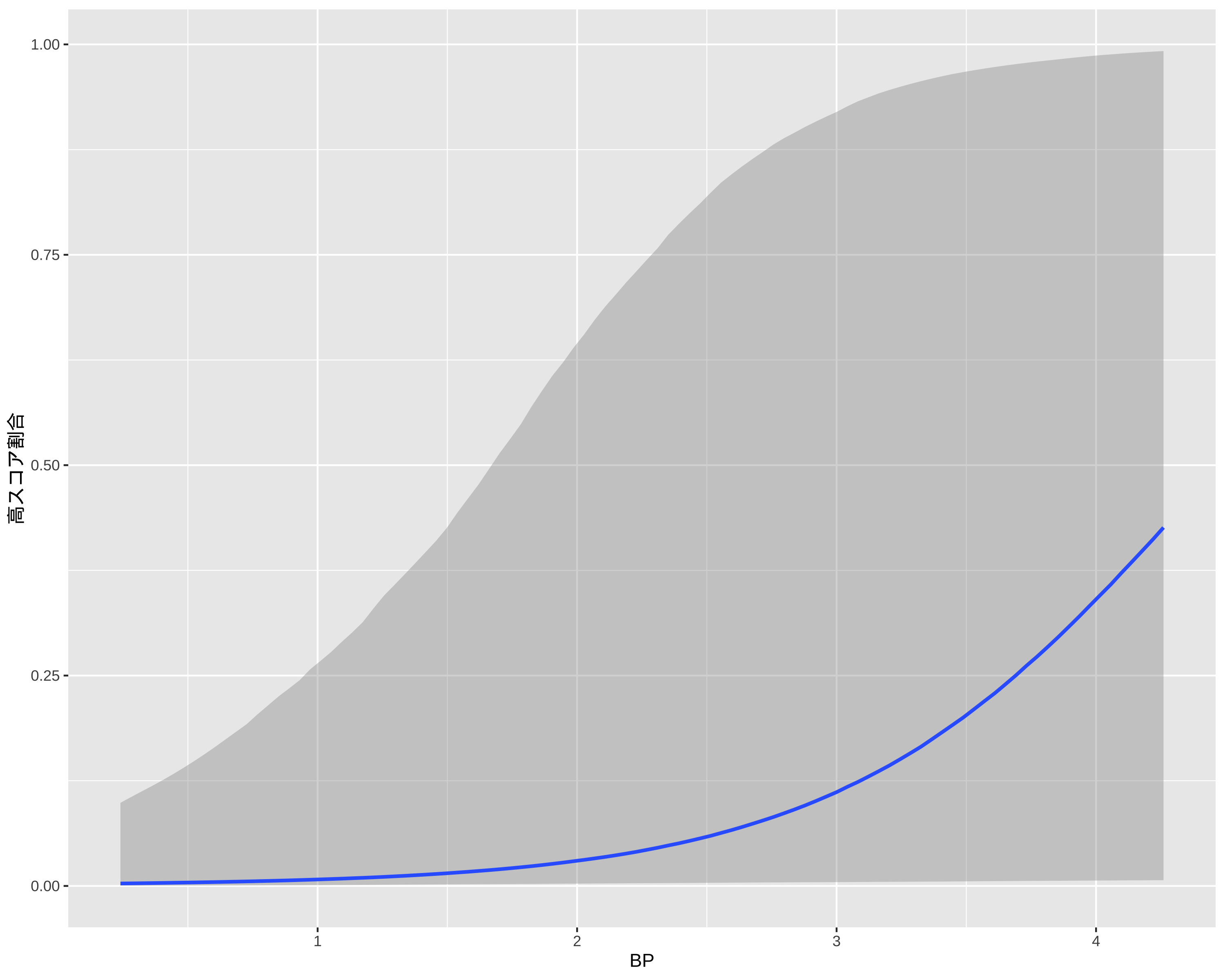
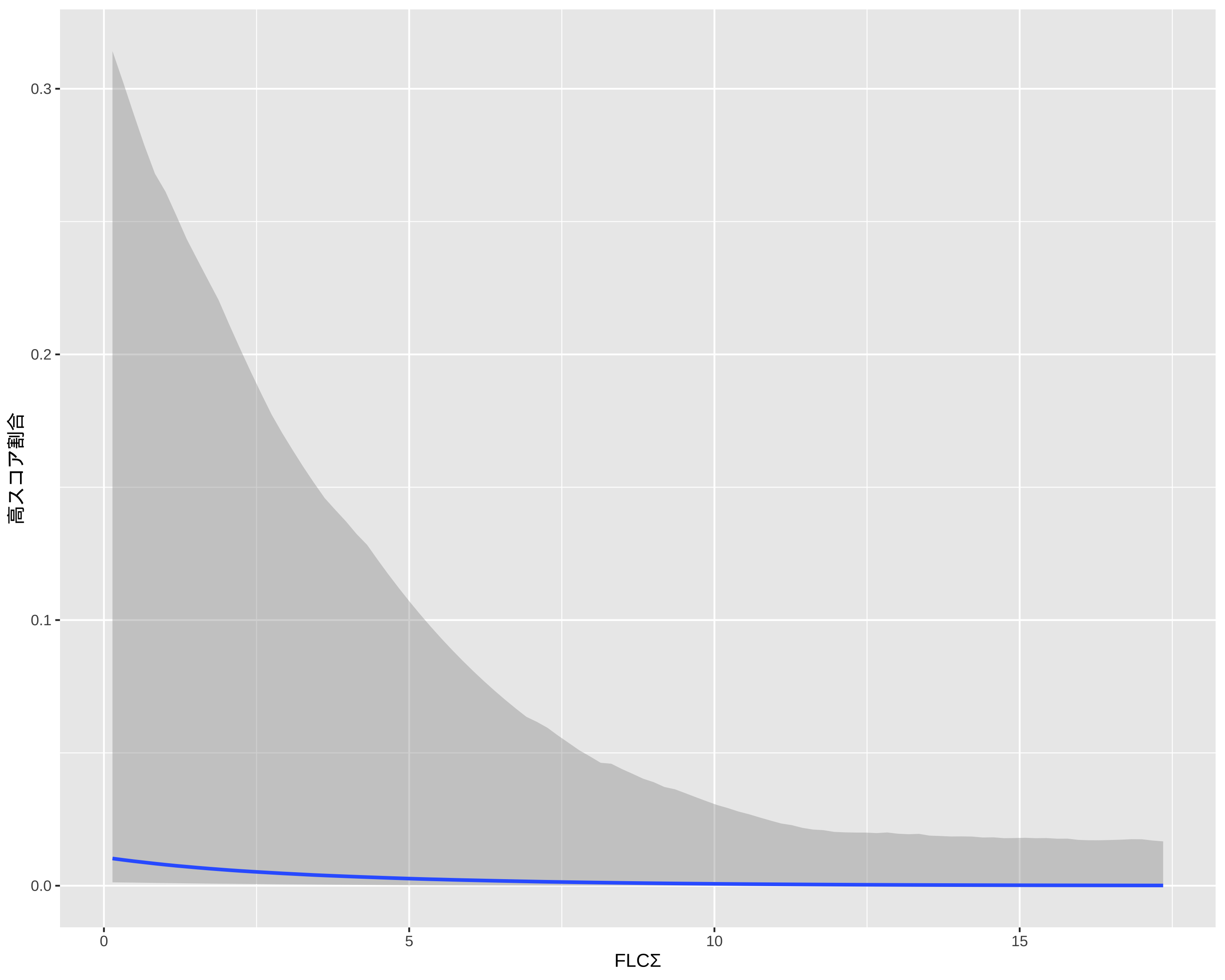
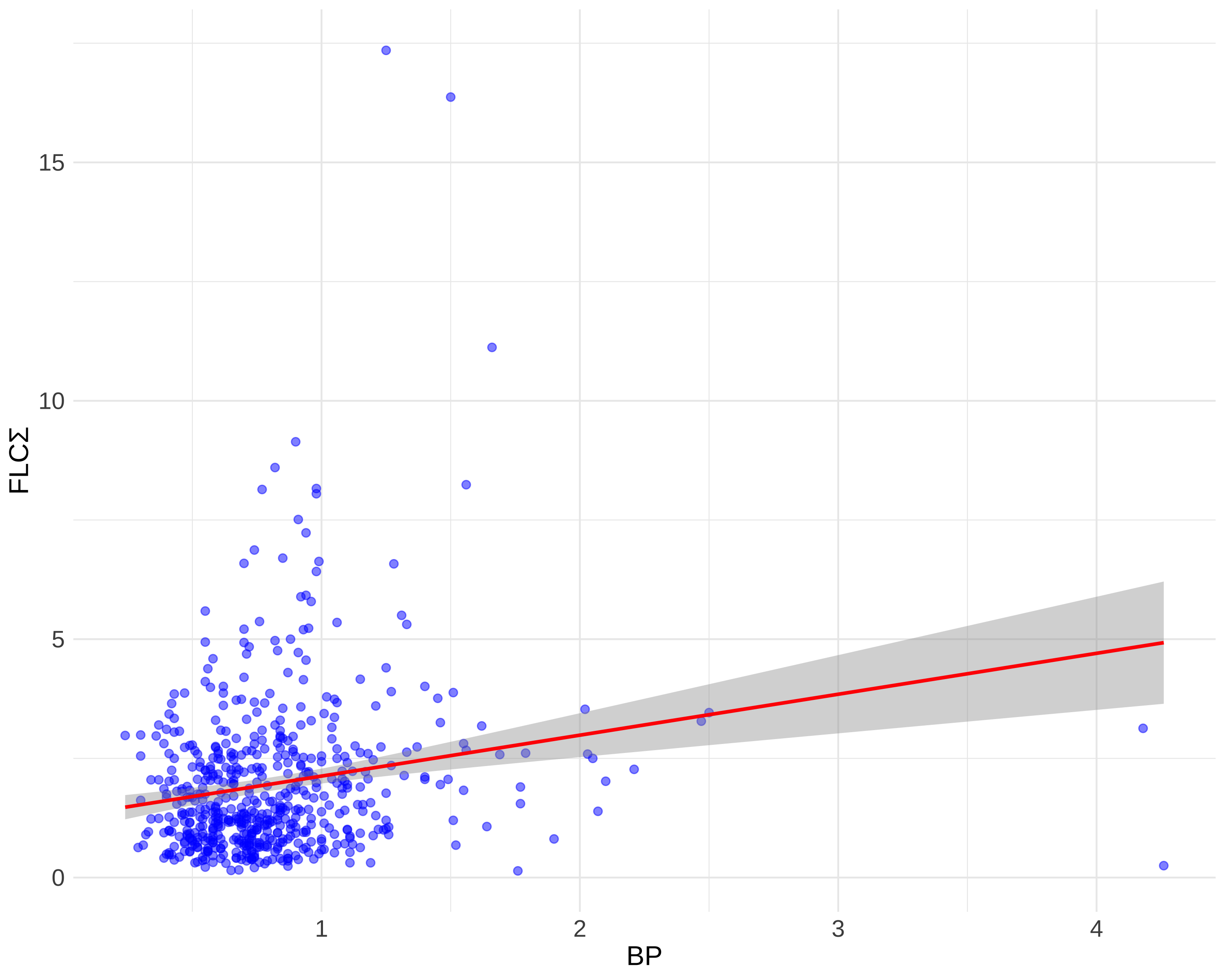
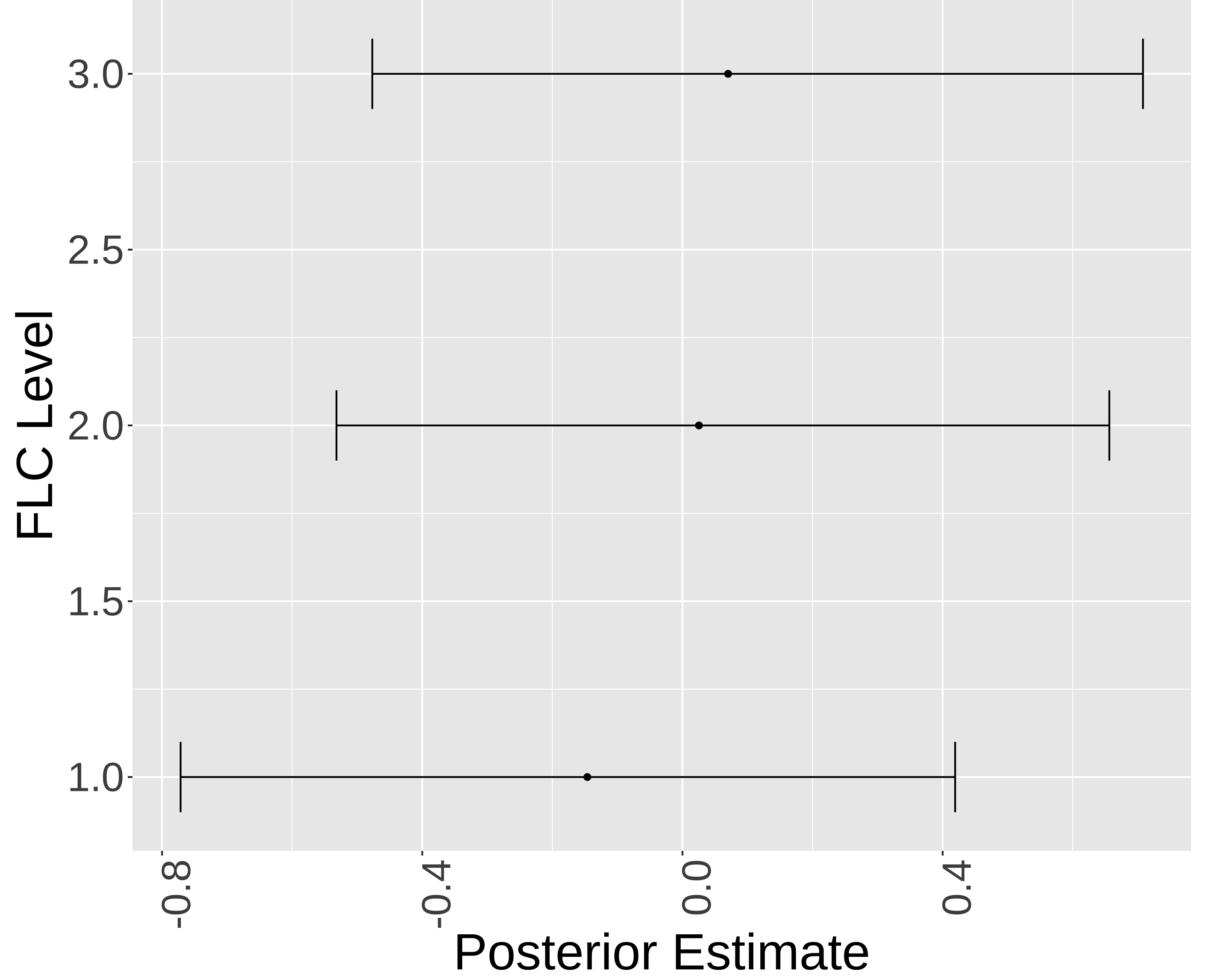
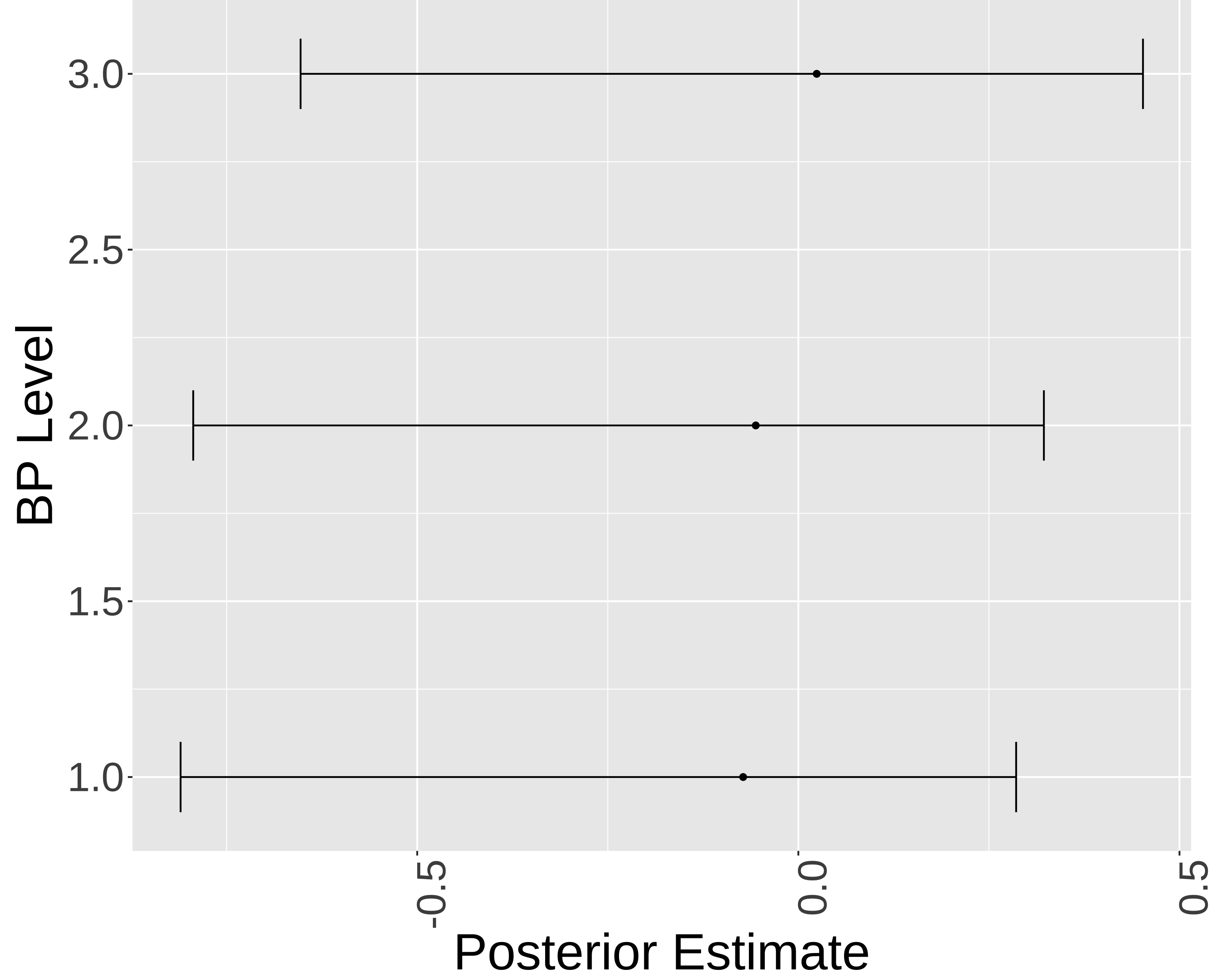
library(brms)formula_2PL <-bf( res ~exp(loggamma) * eta, loggamma ~1+ (1|item), eta ~1+ (1|item) + (1|BP_level),nl =TRUE)fit_2PL <-brm(formula = formula_2PL,data = df_IRT_long,family =brmsfamily("bernoulli", link ="logit"),chains =4, cores =4, iter =8000)saveRDS(fit_2PL, "fit_2PL.rds")
Warning: パッケージ 'brms' はバージョン 4.3.1 の R の下で造られました
要求されたパッケージ Rcpp をロード中です
Loading 'brms' package (version 2.21.0). Useful instructions
can be found by typing help('brms'). A more detailed introduction
to the package is available through vignette('brms_overview').