Welch Two Sample t-test
data: df_long_first$スコア値[df_long_first$昇降格 == 1] and df_long_first$スコア値[df_long_first$昇降格 == 0]
t = 1.6724, df = 24.042, p-value = 0.1074
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.715026 25.923359
sample estimates:
mean of x mean of y
53.66667 42.06250
t.test(スコア値 ~ 昇降格, data = df_long_first, var.equal =TRUE)
Two Sample t-test
data: スコア値 by 昇降格
t = -1.6687, df = 26, p-value = 0.1072
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
-25.898354 2.690021
sample estimates:
mean in group 0 mean in group 1
42.06250 53.66667
Welch Two Sample t-test
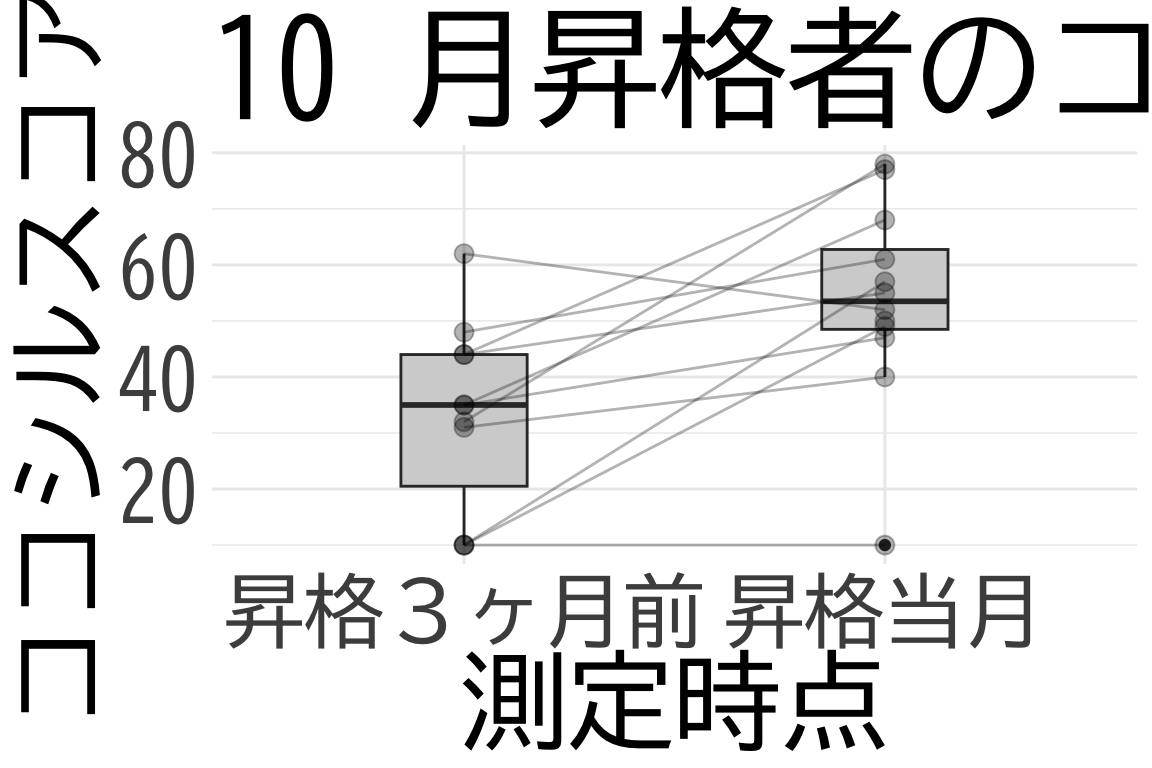
data: df_long_promoted$スコア値[df_long_promoted$測定時点 == 0] and df_long_promoted$スコア値[df_long_promoted$測定時点 == 1]
t = -2.848, df = 20.976, p-value = 0.00964
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-36.073366 -5.623604
sample estimates:
mean of x mean of y
32.81818 53.66667
wilcox.test(スコア値 ~ 測定時点, data = df_long_promoted)
Warning in wilcox.test.default(x = DATA[[1L]], y = DATA[[2L]], ...):
タイがあるため、正確な p 値を計算することができません
Wilcoxon rank sum test with continuity correction
data: スコア値 by 測定時点
W = 21.5, p-value = 0.006606
alternative hypothesis: true location shift is not equal to 0
Welch Two Sample t-test
data: df_long_not_promoted$スコア値[df_long_not_promoted$測定時点 == 0] and df_long_not_promoted$スコア値[df_long_not_promoted$測定時点 == 1]
t = -2.1173, df = 28.982, p-value = 0.04293
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-26.2046758 -0.4536575
sample estimates:
mean of x mean of y
28.73333 42.06250
wilcox.test(スコア値 ~ 測定時点, data = df_long_not_promoted)
Warning in wilcox.test.default(x = DATA[[1L]], y = DATA[[2L]], ...):
タイがあるため、正確な p 値を計算することができません
Wilcoxon rank sum test with continuity correction
data: スコア値 by 測定時点
W = 65, p-value = 0.03018
alternative hypothesis: true location shift is not equal to 0
Warning in wilcox.test.default(diff1, diff2): タイがあるため、正確な p
値を計算することができません
Wilcoxon rank sum test with continuity correction
data: diff1 and diff2
W = 58, p-value = 0.2121
alternative hypothesis: true location shift is not equal to 0
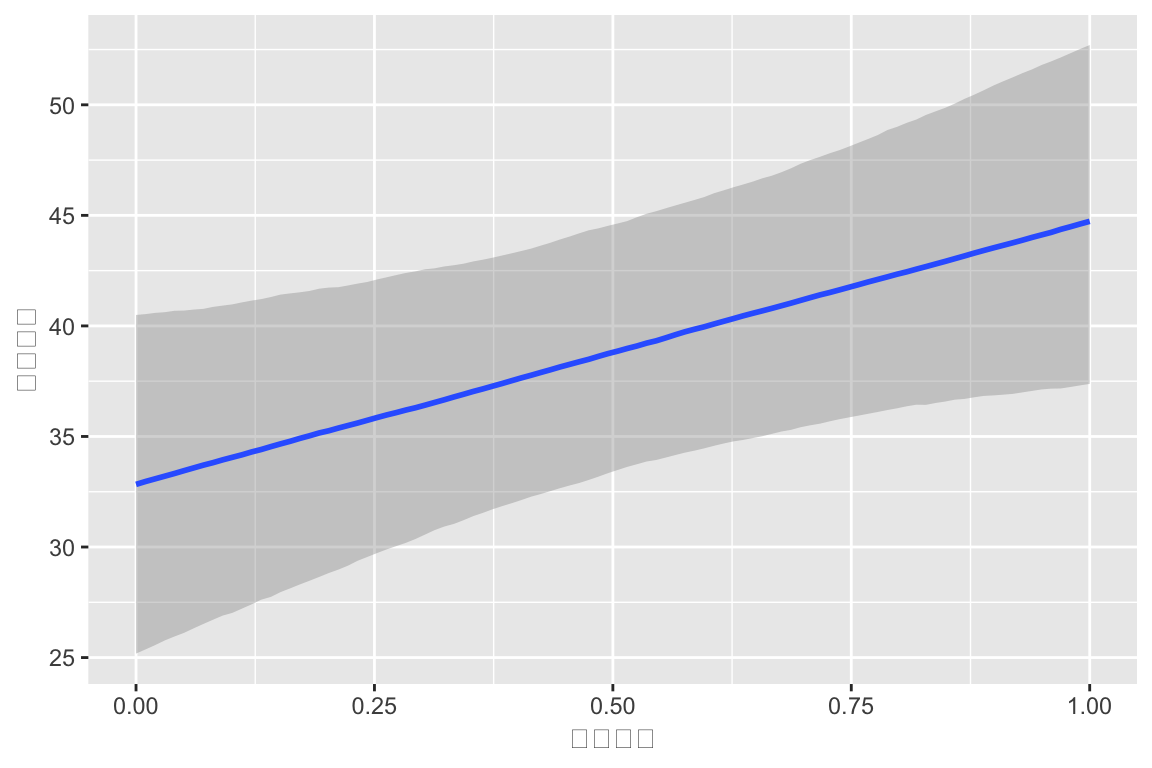
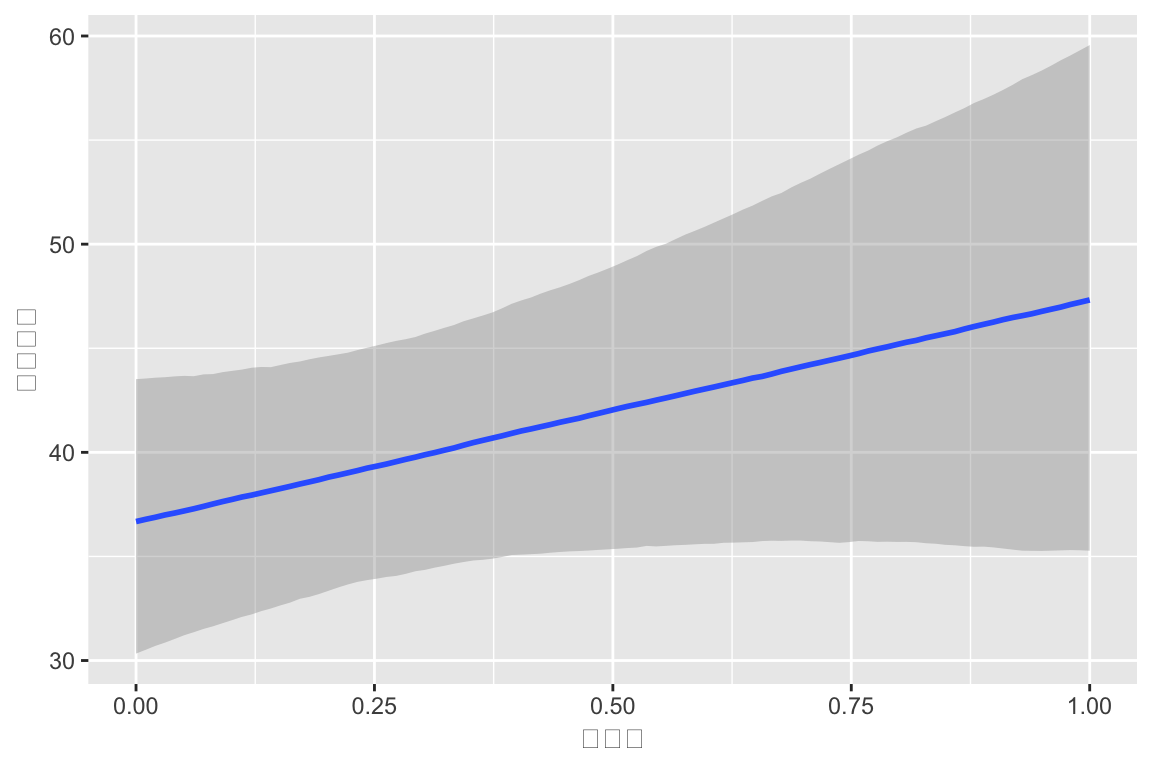
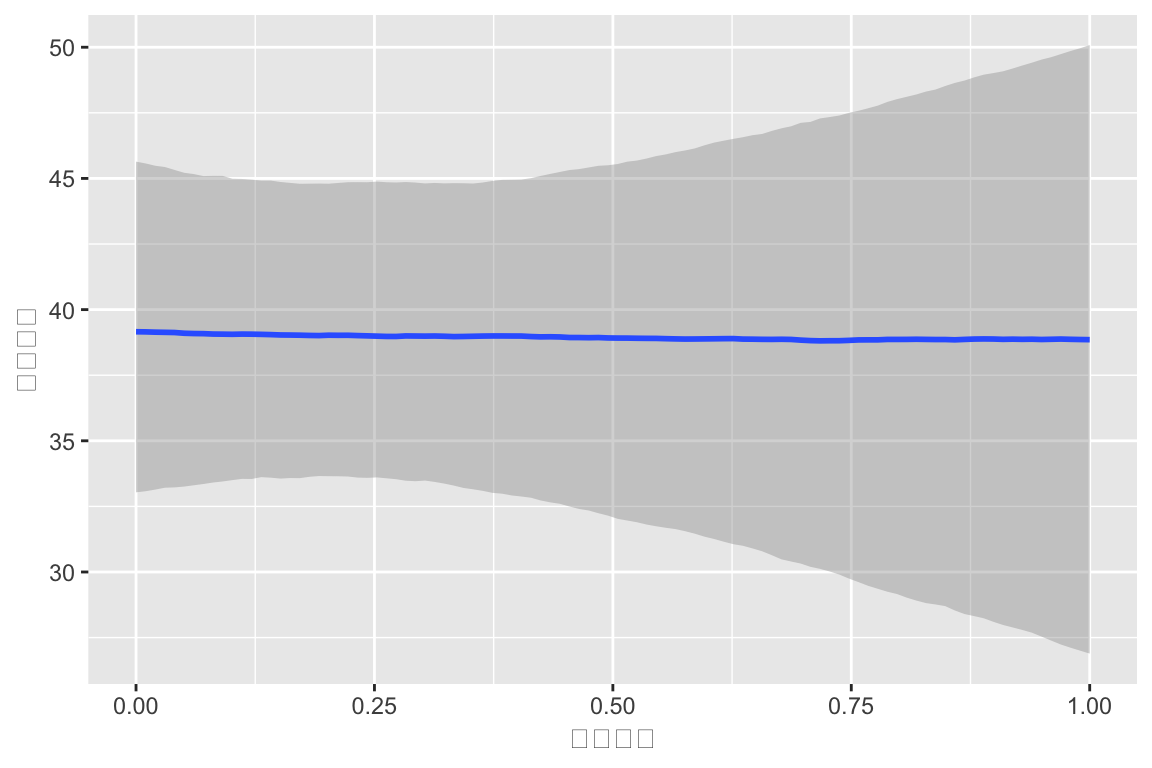
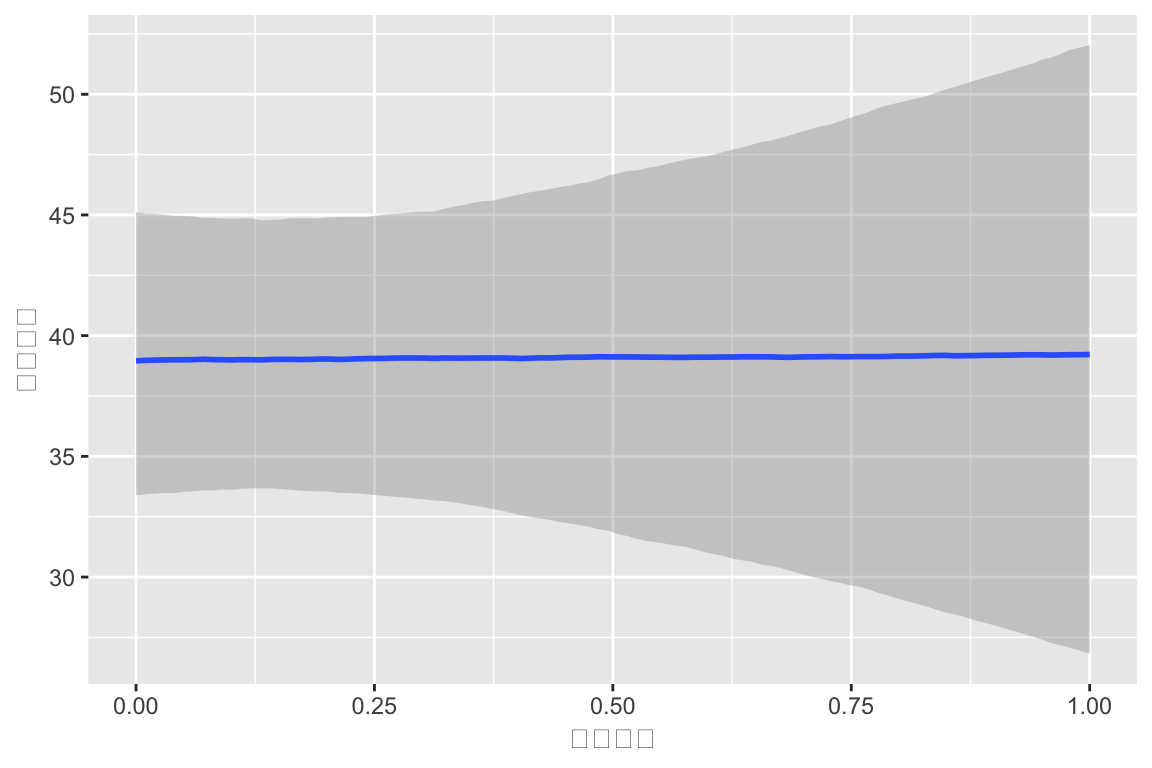
2 測定時点ごとの変動係数モデル
2回の測定で,昇降格の影響が大きく違う可能性があることがわかった.
ランダム係数の間の標準偏差がすごく大きい:\(\sigma=17.04\).
2.1 昇降格の影響だけ変動係数にした場合
library(brms)formula <-bf(スコア値 ~1+ 顧客変更 + 部署異動 + (昇降格 | 測定時点))fit <-brm(formula, data = df_long, chains =4, cores =4, iter =10000)
summary(fit)
Warning: There were 86 divergent transitions after warmup. Increasing
adapt_delta above 0.8 may help. See
http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
Family: gaussian
Links: mu = identity; sigma = identity
Formula: スコア値 ~ 1 + 顧客変更 + 部署異動 + (昇降格 | 測定時点)
Data: df_long (Number of observations: 54)
Draws: 4 chains, each with iter = 10000; warmup = 5000; thin = 1;
total post-warmup draws = 20000
Multilevel Hyperparameters:
~測定時点 (Number of levels: 2)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS
sd(Intercept) 13.40 10.04 1.40 39.27 1.00 7242
sd(昇降格) 15.55 12.76 0.82 49.33 1.00 8309
cor(Intercept,昇降格) 0.11 0.56 -0.91 0.96 1.00 13160
Tail_ESS
sd(Intercept) 5617
sd(昇降格) 6813
cor(Intercept,昇降格) 11316
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 38.00 8.69 20.61 56.10 1.00 6546 5285
顧客変更 -2.44 6.37 -14.93 10.08 1.00 14820 7116
部署異動 -0.54 7.36 -14.78 14.03 1.00 15710 12255
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 18.13 1.85 14.98 22.20 1.00 16138 12716
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
Welch Two Sample t-test
data: スコア値 by 測定時点
t = -3.4348, df = 51.89, p-value = 0.001174
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
-26.257600 -6.890752
sample estimates:
mean in group 0 mean in group 1
30.46154 47.03571
Warning: There were 111 divergent transitions after warmup. Increasing
adapt_delta above 0.8 may help. See
http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
Family: gaussian
Links: mu = identity; sigma = identity
Formula: スコア値 ~ (1 + 顧客変更 + 部署異動 + 昇降格 | 測定時点)
Data: df_long (Number of observations: 54)
Draws: 4 chains, each with iter = 10000; warmup = 5000; thin = 1;
total post-warmup draws = 20000
Multilevel Hyperparameters:
~測定時点 (Number of levels: 2)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS
sd(Intercept) 12.58 9.74 0.86 37.60 1.00 7362
sd(顧客変更) 10.60 9.35 0.42 34.48 1.00 10133
sd(部署異動) 9.37 9.83 0.33 32.83 1.00 10214
sd(昇降格) 16.80 13.66 1.05 52.09 1.00 9434
cor(Intercept,顧客変更) 0.08 0.44 -0.76 0.85 1.00 15044
cor(Intercept,部署異動) -0.05 0.44 -0.83 0.78 1.00 19759
cor(顧客変更,部署異動) -0.03 0.45 -0.83 0.80 1.00 15836
cor(Intercept,昇降格) 0.07 0.44 -0.76 0.83 1.00 15226
cor(顧客変更,昇降格) 0.06 0.44 -0.78 0.84 1.00 14599
cor(部署異動,昇降格) -0.02 0.45 -0.82 0.80 1.00 13589
Tail_ESS
sd(Intercept) 6830
sd(顧客変更) 8109
sd(部署異動) 7919
sd(昇降格) 7091
cor(Intercept,顧客変更) 12853
cor(Intercept,部署異動) 12946
cor(顧客変更,部署異動) 14607
cor(Intercept,昇降格) 12694
cor(顧客変更,昇降格) 13632
cor(部署異動,昇降格) 15194
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 37.68 7.91 21.85 54.69 1.00 6710 8195
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 17.78 1.79 14.69 21.62 1.00 17831 13424
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
Warning: There were 4 divergent transitions after warmup. Increasing
adapt_delta above 0.8 may help. See
http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
Family: gaussian
Links: mu = identity; sigma = identity
Formula: スコア値 ~ (1 | id) + 測定時点 + 顧客変更 + 部署異動 + 昇降格
Data: df_long (Number of observations: 54)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Multilevel Hyperparameters:
~id (Number of levels: 28)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 9.06 3.92 1.18 16.74 1.00 809 1343
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 30.53 3.86 23.02 38.21 1.00 3228 2771
測定時点 12.01 5.44 1.06 22.70 1.00 3282 2449
顧客変更 -0.48 6.47 -13.27 12.18 1.00 3318 2804
部署異動 0.38 6.90 -13.03 13.87 1.00 4063 3082
昇降格 10.61 7.16 -3.27 24.51 1.00 2841 2502
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 15.47 2.23 11.63 20.34 1.00 994 1805
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).